Stop Wasting Your Multi-GPU Setup With llama.cpp
Use vLLM or ExLlamaV2 for Tensor Parallelism
Running 50x requests on 8x GPUs w/ vLLM batch inference—2k tokens/request, 2 mins 29 secs for 50 responses
Table of Contents
What’s The Gist? You should only use llama.cpp when doing partial—or full—CPU offloading of an LLM. But with multi-GPU setups, optimized batch inference with Tensor Parallelism is required, and vLLM or ExLlamaV2—among others—are the correct choices.
Context: Yesterday, I watched @ThePrimeagen live stream (love his streams by the way) where he was stress testing his new Green Tinybox—a 6x RTX 4090 build. His plan was to get the LLM to send and receive concurrent messages and respond to each others, increasing the number and frequency of those messages with time, as a way to stress test those GPUs; and he was using llama.cpp for inference. The llama.cpp part got my attention, and with such a powerful setup, llama.cpp is pretty much a system crippler. Around the 26-minute mark of his stream, I commented on that, and after some back-and-forth, I figured it was best not to hijack his stream and just write this blogpost instead.
In one of his responses while live streaming, Michael(@ThePrimeagen) showed a GitHub thread about llama.cpp supporting concurrent requests, but that is more on the software threading side of things, and llama.cpp is not optimized for Tensor Parallelism and Batch Inference. In this blogpost, we dive into the details of various inference engines, explaining when each one makes sense depending on your setup. We’ll cover llama.cpp for CPU offloading when you don’t have enough GPU memory, how vLLM’s Tensor Parallelism gives a massive boost for multi-GPU systems with batch inference, and why ExLlamaV2’s EXL2 quantization is a great choice for Tensor Parallelism and Batch Inference when memory is limited, but not critically so.
What Are Inference Engines?
In Short: an Inference Engine is a software that understands how to properly send human-input to, and in-turn show human-readable output from, these massive AI Models. In more detail, Large-Language Models (LLMs) are Deep Learning Neural Network Models. The LLMs we use right now come from an Architecture called Transformer which was coined in the infamous paper Attention Is All You Need . Inference Engines usually utilizes the Transformers implemented by the Hugging Face team, which on a lower-level supports the PyTorch, TensorFlow, and Jax libraries allowing for a wide variety of hardware support that those libraries provides tooling for.
The short version above is really all you need to know, so feel free to skip to the next section . But in case you’re curious, Inference Engines also implement a variety of other things that are not necessarily provided out of the box from the Transformers library, such as quantizations, and models’ architectures for those quantizations.
Are you still with me? Good. There are several layers to how an Inference Engine works. It starts with at the bottom level with the hardware you are running (CPU only, CPU and GPU Mixed, GPU only, TPU, NPU, etc), and then it looks into the details of that hardware (Intel, AMD ROCm, Nvidia Cuda, etc), then it goes one level higher and tries to figure out whether you are using a quantization (GGUF, exl2, AWQ, etc), or the original safetensor weights, and then the model architecture itself. The model architecture is the secret sauce—which sometimes is released in a training/white paper—of how the model does it magic to make meaningful connections of your input and then produce a—hopefully— meaningful output.
LLM Architectures: A Quick Detour
Imagine Large Language Models as complex Lego sets with Transformers as the basic bricks. However, each set has different instructions—some build from left to right, others can see the whole picture at once, and some might even shuffle the pieces around for a unique approach. Plus, each set might have its own special pieces or ways of snapping the Legos together, making each model unique in how it constructs or understands language.
There are many architectures out there, what we need to keep in mind is that:
- They share core techniques and concepts—mainly the Transformer architecture;
- They enhance on-top of them with layers of complexity that make them unique and perform differently than other architectures.
This means code implementation for how they’re understood—AKA Inference—is also different.
llama.cpp: Only Use When Doing Partial or Full CPU Offloading
llama.cpp is an Inference Engine that supports a wide-variety of models architectures and hardware platforms. It however does not support Batch Inference, making it less than ideal for more than one request at a time. It is mainly used with the GGUF quantization format, and the engines runs with an okay performance for single-request runs but not much else. The only time I would actually recommend using llama.cpp is when you do not have enough GPU Memory (VRAM) and need to offload some of the model weights to the CPU Memory (RAM).
It is the most popular Inference Engine out there. The Open Source community around it is amazing, and usually pretty fast at supporting new models and architectures, especially for how accessible it is to the wider audicence since it offers CPU offloading. Unfortunately llama.cpp does not, and probably will never, support Tensor Parallelism because most people do not go about spending thousands of dollars on fast-depreciating assets like I do 🤷.
Still, Why?
CPU Offloading
My AI Server has 512 GB of high-performance DDR4 3200 3DS RDIMM memory, which delivers the maximum memory bandwidth allowed by the CPU architecture. Accompanied with AMD Epyc Milan 7713 CPU, I was able to get approximately 1 token per second solely through CPU offloading of DeepSeek v2.5 236B BF16 model, which might sound okay but it really is not. To illustrate why this is suboptimal, utilizing 8x GPUs of my 14x GPU AI Server , and with GPU-only offloading, my server could handle approximately 800 tokens per second while processing 50 asynchronous requests on Llama 3.1 70B BF16 through vLLM’s Batch Inference utilizing Tensor Parallelism.
Tensor Parallelism and Batch Inference with vLLM
At a high level, Tensor Parallelism distributes the computations of each layer of the model across multiple GPUs. Rather than performing an entire matrix multiplication on a single GPU, the operation is partitioned so that each GPU processes a fraction of the workload, this allows for each GPU to runn different parts of different layers simultaneously, yielding to results being computed exponentially faster.
Tensor Parallelism is critical for Multi-GPU setups—and as a rule of thumb, TP loves 2^n hence the 8x GPUs for running the model below—and in the case of stress testing a system, it is better to be done in parallel rather than sequentially. What happens when you’re trying to get LLMs to talk with each other using llama.cpp is that the engine is crippling those GPUs and making them wait for their turn one-after-another.
The cover of this blogpost is a screenshot from a script that I ran with 50 asynchronous requests, ~2k tokens per request, which all-in-all took 2mins 29secs with vLLM running Llama 3.1 70B BF16. It could have been a lot faster if I used an INT8 quantization or lower. And adding speculative decoding and/or embedding model in the mix would make things even faster. This would not have been possible without the Batch Inference that vLLM provides by utilizing Tensor Parallelism.
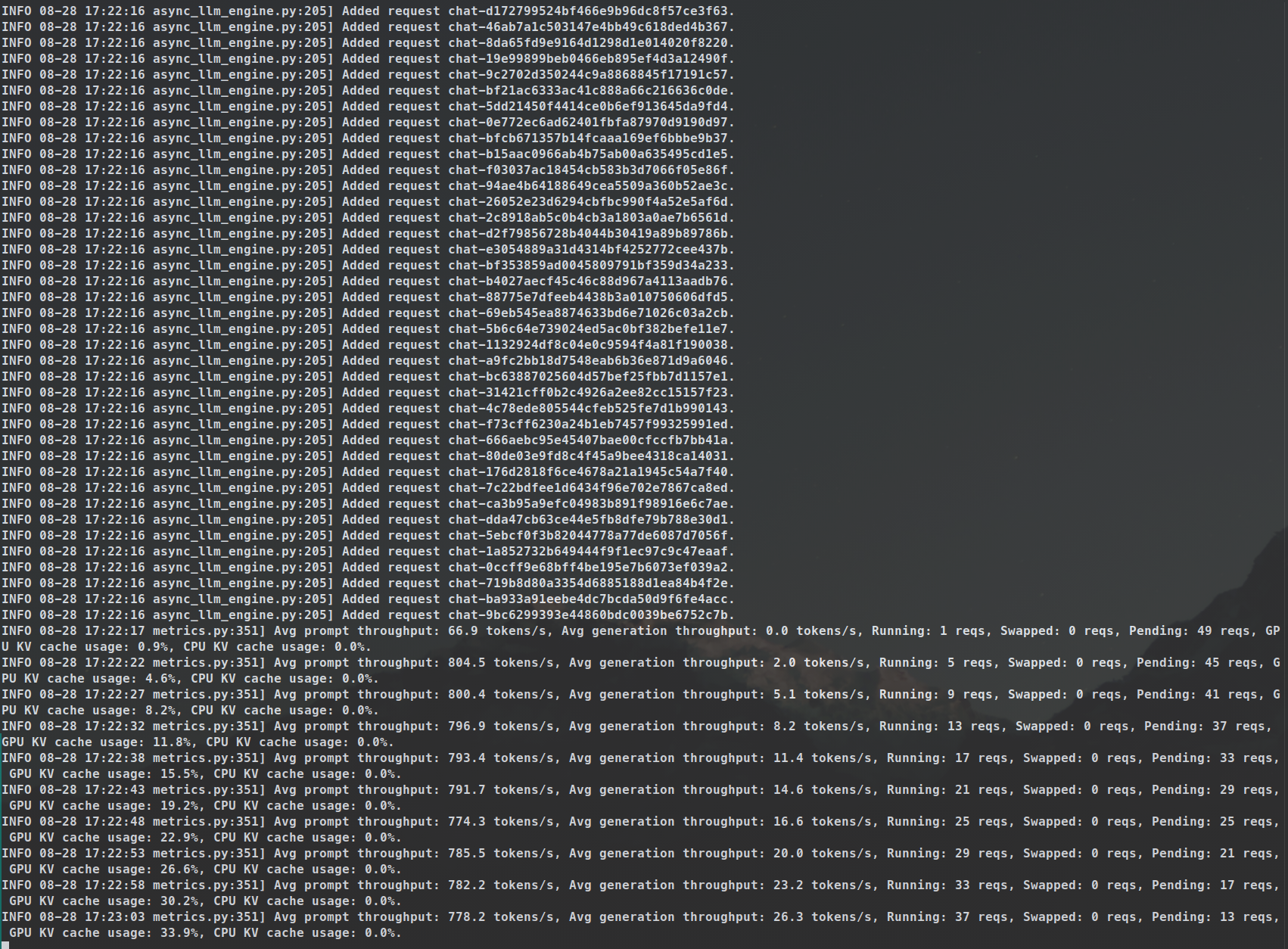
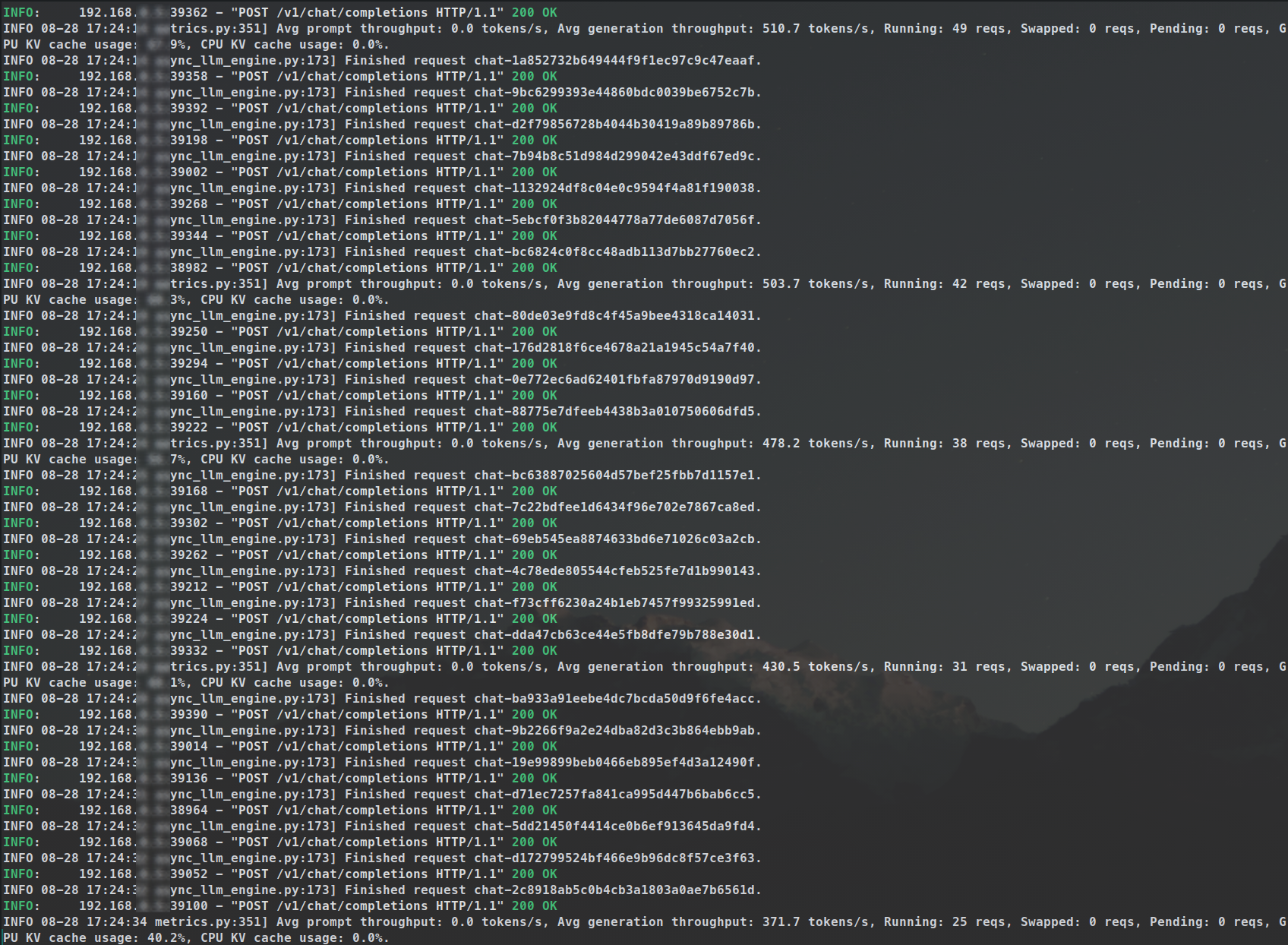
Later on, I ran the same script shown above with over 10k requests for synthetic data generation, and the runtime held true.
ExLlamaV2 and Tensor Parallelism
To utilize a Multi-GPU setup properly, you need an inference engine that supports Tensor Parallelism. vLLM, in addition to Aphrodite, Sglang, TensorRT-LLM, and LMDeploy, all support Tensor Parallelism Batch Inference, and are GPU-only Inference Engines.
Another one is ExLlamaV2 is a GPU-only inference engine, and just this last fall it introduced Tensor Parallelism. I have been a fan of ExLlamaV2 for quite sometime, and it was my main driver inference engine when I had 1 & 2 GPUs. This winter I started using it more as their Tensor Parallelism implemention matured, which allows me to use exl2 quantized models to batch serve requests. ExLlamaV2 has its own EXL2 quantization to the world, which is now supported by multiple inference engines due to its huge upside in VRAM
Final Words: Do Not Use Ollama
Ollama is a wrapper around llama.cpp, and in my opinion it is a tool that sets environment variables, does a bad job at calculating VRAM splits and offloading, and leads to a lot of frustration. It is great if you have only 1 GPU and don’t want to do much except running basic models for chat sessions; anything beyond that and it isn’t worth using.
Until next time.