First Came The Tokenizer
Why the Humble Tokenizer Is Where It All Starts
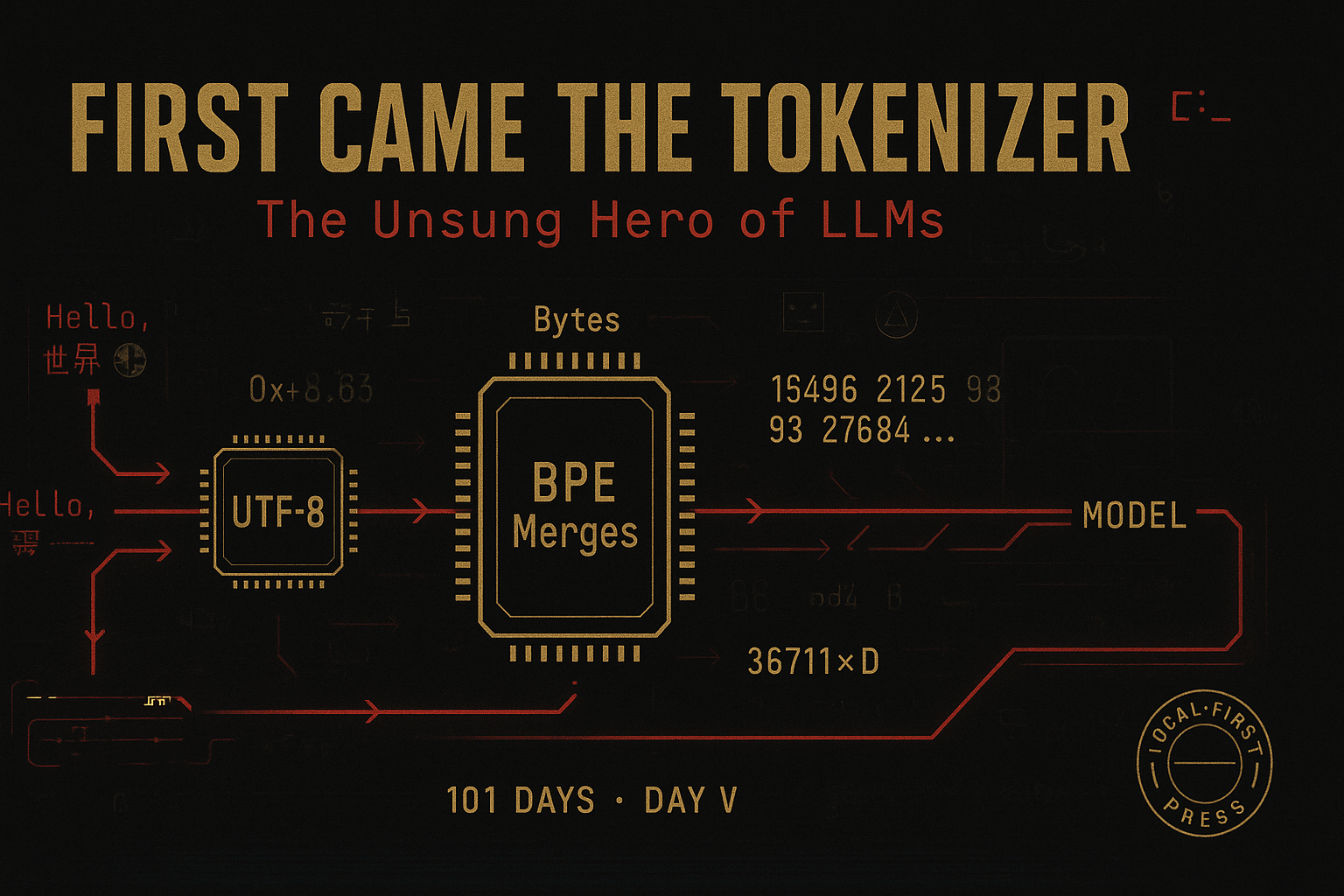
Table of Contents
This is blogpost #5 in my 101 Days of Blogging series. If it sparks anything; ideas, questions, or critique, my DMs are open. Hope it gives you something useful to walk away with.
Before Everything
Before an LLM has a chance to process your message, the tokenizer has to digest the text into a stream of (usually) 16-bit integers. It’s not glamorous work, but make no mistake: This step has high implications on your model’s context window, training speed, prompt cost, and whether or not your favorite Unicode emoji makes it out alive.

www.ahmadosman.com/tokenizer
Tokenizers: The Hidden Operators Behind LLMs
- Models speak numbers, not words. Tokenizers are the translation layer between your text and the neural network continous vector space. No tokenizer, no language model (unless you’ve got half a million neurons dedicated to memorizing the English dictionary).
- They determine how much your prompt “really” costs. A string that looks tiny to you can balloon into dozens of tokens (Chinese, Japanese, and Korean-aka CJK-writing systems are the most prone to this).
- They define what’s “unknown.” Choosing the wrong tokenizer could potentially lead to half your prompt getting replaced with
[UNK]tokens, blowing up meaning and introducing all sorts of headaches downstream. Picking the right tokenizer for the task is crucial, and you minimize that mess by striking a balance between vocabulary size and granularity.
From Whitespace to Subwords: A Lightning Tour
Let’s run through the main flavors of tokenizers, in true “what do I actually care about” fashion:
Word-level
The OG tokenizer. You split on whitespace, assign every word an ID. It’s simple, but your vocab balloons to 500,000+ for English alone, and “dog” and “dogs” are considered different vocabs.
Character-level
Shrink the vocab down to size, now every letter or symbol is its own token. Problem: even simple words turn into sprawling token chains, which slows training and loses the semantic chunking that makes LLMs shine.
Subword-level
This is where the modern magic happens. Break rare words into pieces, keep common ones whole. This is the approach adopted by basically every transformer since 2017: not too big, not too small, just right for GPU memory and token throughput.
Tokenizer Algorithms
Here are the big players, how they work, and why they matter:
Byte-Pair Encoding (BPE) — Used in GPT family, RoBERTa, DeBERTa
How it works:
- Starts with all unique characters (or bytes) as the base alphabet
- Repeatedly merges the most frequent adjacent pair of symbols (characters or previously merged chunks)
- Continues until the target vocabulary size is reached
Why it matters:
- Reduces vocab size while capturing frequent subword units
- Helps with rare words, typos, and multilingual text
- Strikes a balance between simplicity and performance
- Widely used due to its effectiveness and generality
WordPiece — Used in BERT and related models
How it works:
- Similar to BPE, but merges pairs that maximize overall likelihood based on a probabilistic model
- Often creates unexpected subword chunks for better statistical fit
- Uses special prefixes (like “##”) for tokens inside a word
Why it matters:
- More flexible and context-sensitive splits
- Slightly improves performance, especially for morphologically rich languages
Unigram LM — Used in T5, mBART, XLNet
How it works:
- Starts with a large pool of possible subwords, each with an assigned probability
- Iteratively prunes away the least likely subwords
- Finds the tokenization that maximizes the product of the subword probabilities for each input
Why it matters:
- Probabilistic, pruning-based method gives flexible, efficient vocabularies
- Well-suited for diverse or multilingual data
- Famously implemented in SentencePiece
SentencePiece — Designed for multilingual/agglutinative languages
How it works:
- A toolkit that implements both BPE and Unigram LM
- Operates directly on raw UTF-8 bytes, with no need for whitespace-based pre-tokenization
- Treats input as a raw stream (great for languages with no spaces)
Why it matters:
- Handles languages without spaces (e.g., Japanese, Chinese)
- Robust to messy, real-world text
- Flexible for diverse token boundaries that break other tokenizers
Byte-level BPE (tiktoken) — Used in GPT-2, GPT-4o, OpenAI API
How it works:
- Uses raw bytes (0–255) as the base alphabet
- Every character, emoji, or symbol is broken into bytes; BPE merges then apply
- Totally agnostic to language or script
Why it matters:
- Universal: can tokenize any Unicode text (emojis, all scripts, etc.)
- No hand-tuned rules needed
- Tradeoff: more tokens for common words in most languages (inflates token counts), but ensures universal coverage and robustness
Vocabulary Size: A Tradeoff
Scaling law nerds (hey, that’s us) know: as you scale up your model, you need to scale your tokenizer’s vocabulary too, which in turn helps with optimizing how efficiently your model chews through raw text.
Take Llama 3, for example: its tokenizer jumped to a whopping 128K vocab size, compared to Llama 2’s more modest 32K. Why? With a bigger vocab, each token can represent longer or more meaningful text chunks. That means your input sequences get shorter (the model has fewer tokens to process for the same amount of text), which can speed up both training and inference. You’re basically packing more info into every step.
But there’s no free lunch. A larger vocabulary means your embedding matrix-the lookup table mapping token IDs to vectors-grows right along with it. More tokens = more rows = more parameters = more GPU RAM required. For massive models or memory-constrained deployments, that can be a real pain. You also run into diminishing returns: after a certain point, adding more tokens doesn’t buy you much, but still taxes your hardware.
On the flip side, if your vocabulary is too small, your tokenizer starts breaking up words into lots of tiny pieces (“subwords”). Your model ends up wrestling with long, fragmented sequences, burning compute on basic reconstruction instead of actual language understanding. That’s inefficient, especially for languages with rich morphology or lots of rare words.
So where’s the “just right” zone? It depends. The ideal vocab size is a balancing act:
- Compute budget: More vocab = bigger embedding = more FLOPs/memory.
- Inference setup: Shorter sequences can mean faster inference, but not if you’re swapping to disk for embeddings.
- Languages covered: Multilingual or domain-specific tokenizers might need bigger vocabularies to avoid splintering key terms.
At the end of the day, picking a vocab size isn’t just a technical tweak, it’s a core design choice that shapes everything downstream, from model cost to multilingual robustness. Getting this wrong means you’re either bottlenecked by hardware or wasting compute on needlessly long sequences.
Tokenizer Quirks: Fun Ways To Sabotage Yourself
- Whitespace weirdness. Some tokenizers nuke leading spaces (GPT-2), others encode them as tokens (Llama). This results in mystery bugs, mismatched generations, and hours of “why is my model doing this.”
- Special tokens.
[CLS],<s>,<pad>,<|endoftext|>, etc. They count toward your length limit and love to leak into generations if you forget to mask them. - Multilingual headaches. Using an English-centric vocab for CJK or agglutinative languages? Get ready for triple token counts and a swamp of
[UNK]s. Use a language-aware SentencePiece to avoid the suffering. - Version drift. Mismatch your tokenizer and model vocab file-just once-and expect nothing but total garbage output.
Picking a Tokenizer for Your LLM Playground: My Cheat Sheet
Want to skip the theory and just get your hands dirty? Here’s the cheat sheet:
If you care about…
Training speed & GPU RAM:
- Grab: Byte-level BPE (
tiktoken) - Why: Minimal merges, Rust-fast decoding, OpenAI’s secret sauce.
On-device (mobile) inference:
- Grab: WordPiece
- Why: Smaller embedding tables, less RAM pain, still competitive on sequence length.
Cross-language coverage:
- Grab: SentencePiece Unigram
- Why: Train once, cover dozens of scripts and languages.
DIY research tinkering:
- Grab: Hugging Face
tokenizers - Why: Python bindings, Rust core, built-in introspection.
Final Words: The Humble Tokenizer Is Doing More Than You Think
Tokenizers are never the sexiest part of an LLM stack, but they are very impactful. Understand them, and you control real prompting costs, inference throughput, and the very shape of what your models can express.
Next time your model is spitting out garbage or can’t fit your prompt, don’t blame the GPUs 😝
Give a little respect to the humble tokenizer.
In the meantime, if you want to see tokenizers in action, check out www.ahmadosman.com/tokenizer .
PS: Remember, you can always use my DeepResearch Workflow to learn more, if you’re stuck, need something broken down to first principles, want material tailored to your level, need to identify gaps, or just want to explore deeper.