No, RAG Is NOT Dead!
RAG Is Dead?! Long Live Real AI!

Table of Contents
Is RAG Dead?
This blogpost was published on my X/Twitter account on April 11th, 2025 .
On Friday, April 11, 2025, I hosted a space titled “Is RAG Dead?” with my friend Skyler Payne . Skylar is ex-Google, ex-LinkedIn, currently building cutting-edge systems at Wicked Data and helping enterprises bring real AI solutions to production. This space has been on my mind for quite sometime now. There is this opinion floating around that “LLMs have 1M+ token context length now! We don’t need RAG anymore!” This isn’t just a bad take. It’s a misunderstanding of how actual AI systems are built. So, Skylar and I decided to host this space and talk it out together. What followed was one of the most technical, honest, no-bullshit convos I’ve had in a while about the actual role of RAG in 2025 and beyond.
If you don’t know me, I’m the guy with the 14x RTX 3090s Basement AI Server . I’ve been building and breaking AI systems for quite sometime now, I hold dual degrees in Computer Science and Data Science. I am also running a home lab that looks like it’s trying to outcompute a small startup (because it kind of is). I go deep on LLMs, inference optimization, agentic workflows, and all the weird edge cases that don’t make it into the marketing decks.
Let’s break it down.
First Off: What Even Is “RAG”?
Skyler opened by asking the obvious but important question: when people say “RAG,” what do they even mean?
Because half the time, it’s being reduced to just vector search. Chunk some PDFs, some cosine similarity, call it a day. But that’s not RAG.
Real RAG, at least the kind that works at scale, is more than just a search bar duct-taped to an LLM:
- Retrieval pipelines that actually deliver relevance.
- Intelligent reranking and filtering.
- Guardrails and feedback/eval loops.
- Sometimes even agents.
Also, definitions matter. If your definition stops at vector search and mine includes multi-hop planning and agents, we’re not debating. Understanding that nuance is key before you even ask whether RAG is “dead.” Because until we agree on the same definition, we’re just yelling at each other for the wrong thing.
Bigger Context ≠ Better Retrieval
The main argument against RAG is that LLMs can now eat entire PDFs. “Why retrieve when you can just feed it all in?” Doesn’t work.
Skyler walked us through what entreprises have on their hands:
- Most orgs have terabytes of knowledge. Think pharma companies with 50 years of research PDFs, or a LinkedIn-scale data lakes. You’re not feeding that into a context window, no matter how large.
- Effective Context Length: Benchmarks show useful context recall absolutely falls off a cliff after just some-thousand tokens. For example, the recent Llama 4 Maverick has 10M token context length, however, the effective recall drops to just ~36% after 120k tokens. That’s 120k tokens out of the 10m tokens it’s supposed to be able to handle recalling!
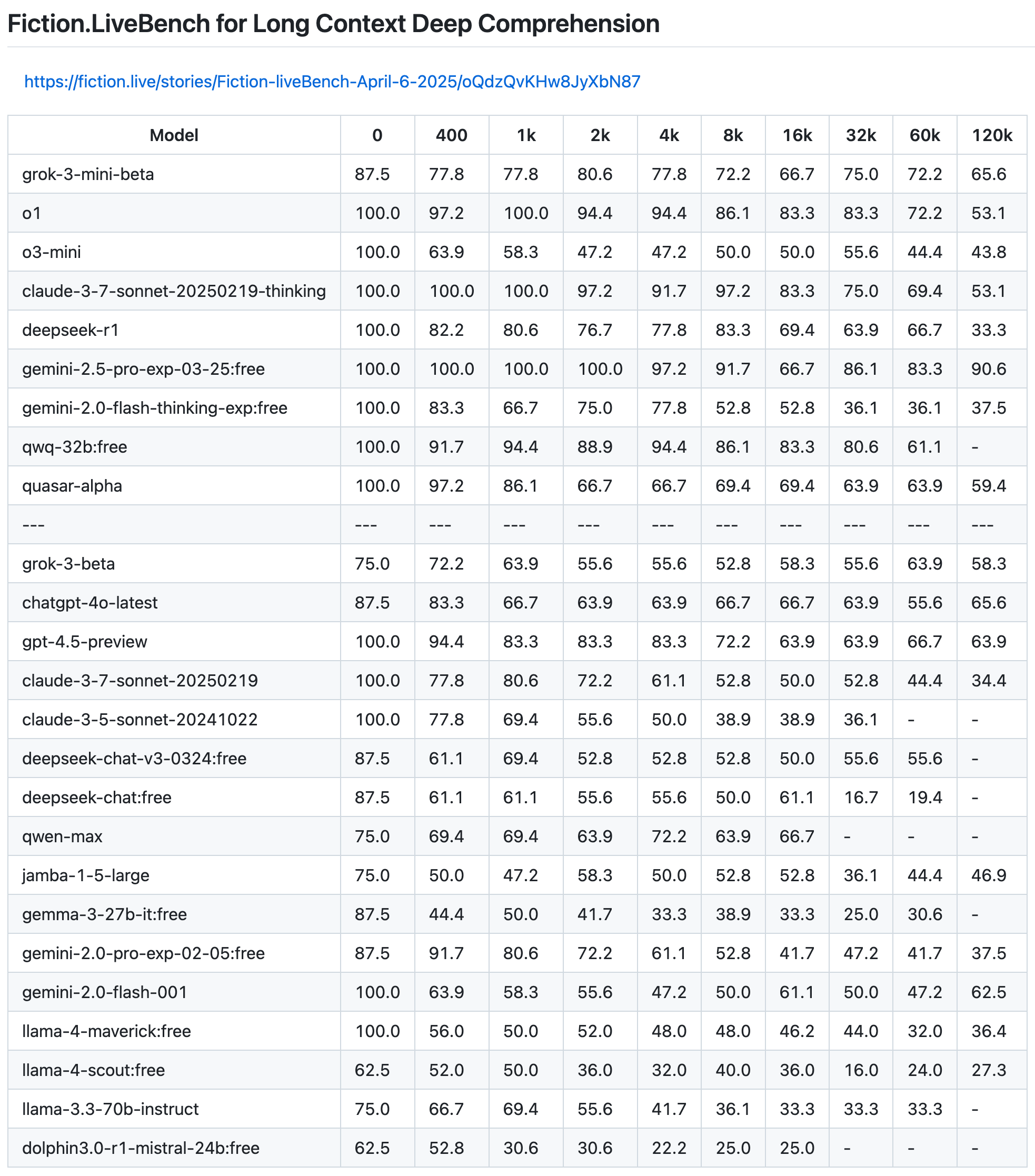
Also, the Lost in the Middle problem is still alive and well in all models to this day. Longer doesn’t mean smarter; it just means more tokens to lose track of your actual signal.
Just because your LLM can technically fit 100K tokens doesn’t mean it can use them.
Fine-tuning = Context Control?

Another thing we tackled: this weird binary people draw between fine-tuning and RAG. It’s not either-or.
Fine-tuning shapes behavior, but ensuring factual accuracy with a constantly shifting data? That’s retrieval.
Do you want to retrain the whole model every time someone updates a PowerPoint? No thanks. That’s dumb, expensive, and unsustainable. RAG gives you dynamic context, on demand. That’s the whole point.
Fine-tuning is for vibes. RAG is for facts.
Most People’s RAG Pipelines Are… Bad
“Most RAG implementations I’ve seen are hacks.” ― Skylar B. Payne
People hack vector DBs to embedding models and call it a day. No eval loop, no telemetry, no feedback from actual users.
What You Actually Need For RAG:
- Evaluation-Driven Development: Log everything—queries, responses, retrieval scores.
- Real-world Datasets: Mirror actual user diversity (emotion, phrasing, intent).
- Actionable Evals: Metrics beyond generic tests. Be domain-specific. Data cleaning is absolutely unavoidable.
Embeddings: Start Simple, Then Specialize
Practical Advice on Embedding Strategies:
- Start general, tune embeddings specifically for your domain.
- For B2B/high-value retrieval? Fine-tune embeddings per client. It’s not optional, it’s a game changer.
Skylar also emphasized logging everything (e.g. chunking) with unique IDs for easy reconstruction and evaluation later.
Agentic Retrieval Comes With a Cost
Agentic RAG: Tools, planners, multi-hop retrievers. Powerful but risky.
Skyler warned that every additional agent means more eval complexity, latency, and edge cases. If your agentic pipeline adds 4x latency for just 0.2% improvement, you haven’t built better RAG.
Evaluate before orchestrating complexity. If you can’t measure the ROI, you’re just cosplaying AI.
Complexity Spirals & Evaluated Sophistication
Just because you can make RAG more complex doesn’t mean you should. Skyler called this “Evaluated Sophistication”: Adding complexity only if it measurably outperforms simpler baselines.
The real question isn’t if your pipeline can chain three hops, it’s whether that chain is worth the complexity.
Final Word
RAG isn’t dead. It’s evolving. Skyler nailed it with a mic-drop line:
“If someone tells me RAG is dead one more time, I’ll just make more money. Because RAG’s not dead.”
He’s right. And everyone building serious AI systems knows: Retrieval isn’t optional, it’s how you ship.
Keep tweeting “RAG IS DEAD” if you want. Some of us are too busy shipping to notice.
P.S. If this was your first time coming across me , you should take a look at my website . It’s mainly technical posts on AI & Infra. Also, I got an About Me page that I think is a fun read.
References
- Skyler’s “Why RAG Is (Still) Not Dead” blogpost
- Skyler’s “AI Observability is Just Observability” blog post
- Skyler’s “Bootstrapping AI Systems with Synthetic Data” blogpost
- AI Engineering by Chip Huyen
- Your AI Product Needs Evals by Hamel
- Systematically Improving Your RAG by Jason Liu
- JinaAI’S Late Chunking in Long-Context Embedding Models
- Anthropic’s contextual retrieval methods
- Fiction.LiveBench for Long Context Deep Comprehension