Serving AI From The Basement — Part II
Unpacking SWE Agentic Framework, MoEs, Batch Inference, and More
Running 50x requests w/ vLLM batch inference — 2k context per request, 2 mins 29 secs for 50 responses
Table of Contents
This is Part II of Serving AI From The Basement Blogpost Series. You can access Part I here .
- In this blogpost:
- SWE Agentic Framework – think of it as the puppet master for coders plus Replit’s next nemesis.
- MoEs (Mixture of Experts) – imagine a team of AI experts, each shouting answers when it’s their topic.
- Quantizations & Mixed Precision – turning AI from gourmet to fast food without losing the flavor.
- Batch Inference – AKA AI’s quiz night, answering all questions at once.
- LLM Architectures – blueprints for our AI friends.
- vLLM and Tensor Parallelism – or the thing that makes big AI models run lean.
- DeepSeek v2.5 – our open weights savior.
- Embedding Models – translating human words into AI-understandable numbers.
- Speculative Decoding – or AI’s attempt at mind-reading, guessing your sentences before you finish them.
Agents, AI, and Replit’s Next Nemesis
For about 3 weeks now, I have been working on a multi-agent system that simulates a team of Software Engineers; this system assigns projects, creates teams and adds members to them based on areas of expertise and need, and asks team members to build features, assign story points, have pair programming sessions together, etc. Started mainly for fun and exploration, however, last week the following paper was released: Agents in Software Engineering .
The paper delivers an overview of a framework that allows large language models play nicely within a sandbox for Software Engineering, and it cites several dozens of papers that implement task-specific agents. Since then, I have been a lot more motivated to get this agentic framework semi-decently put together, and it got me wondering: maybe it will beat Replit?
What are Agents?
Agents are Python scripts. Bash scripts. C++ programs. Or whatever. Agents are anything that can hit an OpenAI compatible API endpoint. Agents are anything that can talk with an inference engine sending inputs and receiving outputs. What makes them agentic is being permissive –while sandboxed– and having a few dozens of them running iterations for you to do A/B testing on.
I like playing with these toys because I do not know what the outcome might be. I really don’t. It differs from one model to another. Simple changes in Sampling Parameters might cause things to fully break or make things very interesting. It is a very fragile ecosystem right now.
However, I also believe that there is a very high possibility that what might not seem to be working with the current generation of models might be very feasible in a generation or two from now. So, I am going to build stupid toys, break them, iterate over them, and wait for a moment where something new, plug-and-play, becomes available for me throw in.
Up Late, Fighting Battles No One Knows About 😅
The time is 02:43 AM as I am writing this paragraph, Mr. Robot OST is playing in the background (all 8 volumes on loop, shuffled of course I am not an animal), and I just spent about ~5 hours on what I assumed would be a quick 2-3 mins task. In that time, I read about half a dozen quantization algorithms, another half dozen model architectures, and dove into GitHub exploring inference engines, libraries, and a lot of LLMOps tools that I was not aware of. I cannot sleep because I like when things work and I DO NOT like when things do not work. Stubbornness is essential when working in Software.
The vLLM inference engine, which I primarily use and is also widely utilized as a kernel in other engine implementations including SGlang , Aphrodite , and TensorRT-LLM , supposedly allows for Mixed Precision quantizations. However, the reality is more complex…
Wait, 192GB of VRAM Isn’t Enough?!
Well, as I said, it is complicated… My AI Server has 192GB of VRAM, and sometimes I would move my main RTX 4090 & RTX 3090 from my PC to the AI Server and that increases the VRAM to 240GB, and I am not typically a fan of that and neither is Tensor Parallelism. Llama 3.1 70B BF16 (Full Precision) has been my main driver model since release, and sometimes I switch to Llama 3.1 405B INT4 (Mixed Precision: 4-bits weights and 16-bits activation, aka W4A16).

For my SWE multi-agent system, I decided to switch the to DeepSeek v2.5 . DeepSeek v2.5 is a State of The Art (SOTA) coding model, it is a Mixture of Experts (MoE) model with 128k context length, made of 236B parameters. and according to benchmarks the only model that beats it is Claude 3.5 Sonnet. But first, let’s understand a few things.
LLM Architectures & Inference Engines
Imagine Large Language Models as complex Lego sets with Transformers as the basic bricks. However, each set has different instructions—some build from left to right, others can see the whole picture at once, and some might even shuffle the pieces around for a unique approach. Plus, each set might have its own special pieces or ways of snapping the Legos together, making each model unique in how it constructs or understands language.
There are many architectures out there, what we need to keep in mind is that 1) they share core techniques and concepts –mainly Transformers and Attention– and 2) they enhance on-top of them with layers of complexity that make them unique and perform differently than other architectures. This means code implementation for how they’re understood –inference– is also different.
The –non-commercial– inference side is hectic. Each new model that gets released on a new–or a new iteration of an–architecture means inference engines need to implement that architecture for inference. The best inference engines written to specs are definitely the ones provided by the model’s authors. Sometime ago, I came across a tweet by someone at xAI that said he would never trust any inference engine to run a model except the one provided by the model’s authors, and now I see why he had that opinion.
Mixture of Experts Architectures
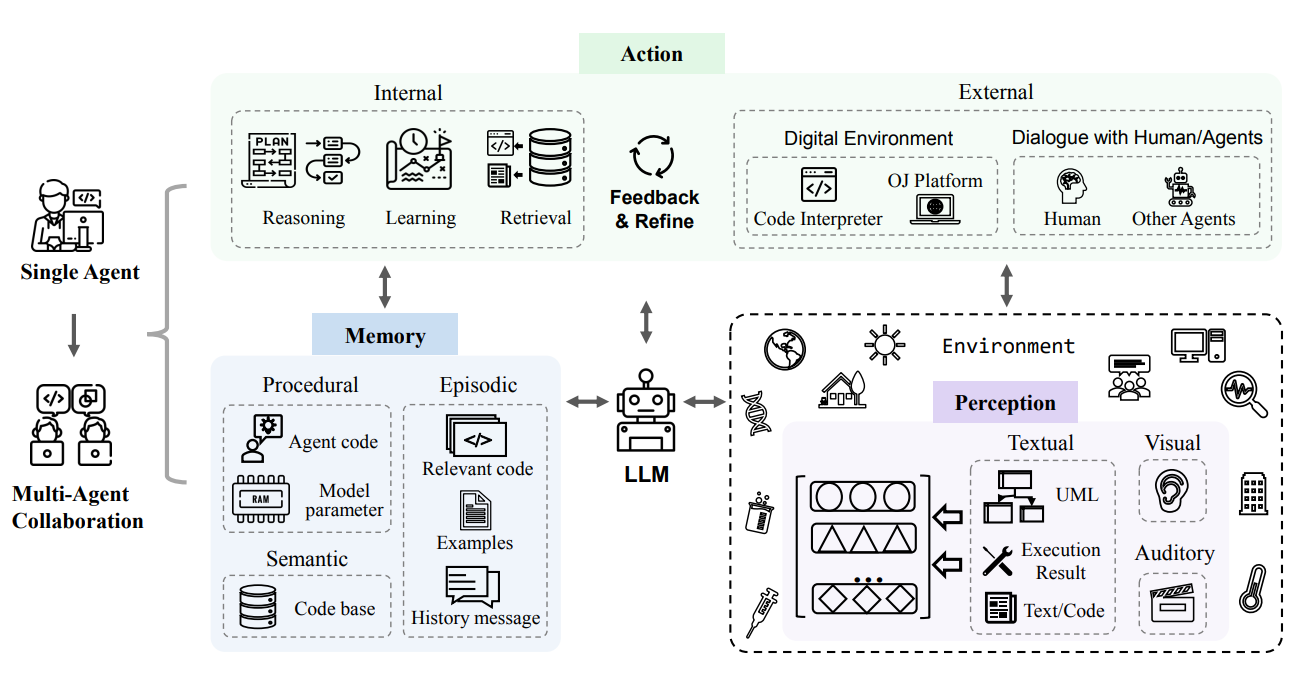
A Mixture of Experts architecture in Large Language Models integrates multiple specialized sub-models (experts) to handle different aspects of language processing, so you can say that it has multiple sub-models to handle different programming languages/technologies, routing and re-routing to the most appropriate sub-model as a user provides it with instructions. For example, the DeepSeek v2.5 model is made of 236B total parameters, and for each token it processes, it redirects that token to the 21B most probable parameters.
For comparison, this is Llama’s architecture.
MoE architectures are a lot more complex to implement inference for, and to do so supporting different quantizations is another layer of complexity that does not help much.
Batch Inference and CPU Offloading
The server has 512 GB of high-performance DDR4 3200 3DS RDIMM memory, which delivers the maximum memory bandwidth allowed by the CPU architecture. Accompanied with AMD Epyc Milan 7713 CPU, I was able to get approximately 1 token per second solely through CPU offloading of DeepSeek v2.5 236B BF16 model, which might sound okay but it really isn’t. To illustrate why this is suboptimal, utilizing all 8x GPUs and GPU-only offloading, the server could handle approximately 800 tokens per second while processing 50 asynchronous requests on Llama 3.1 70B BF16 through vLLM’s batch inference. We will get back to that in a later section of this blogpost.
Also, what is the use of these GPUs if I relied on the CPU? I don’t want to deal with buyer’s remorse here. Seriously though, in the context of an agentic system, storage, memory, latency, and request volume are the core components to leverage. GPU offloading is absolutely necessary for that.
vLLM, ExLlamaV2, Llama.cpp, and Tensor Parallelism
To utilize this server properly I need an inference engine that supports Tensor Parallelism. vLLM, in addition to Aphrodite, Sglang, TensorRT-LLM, and LMDeploy, all support Tensor Parallelism and are GPU only batch inference engines.
Inference Engines
ExLlamaV2 is a GPU-only inference engine, and just a month ago it introduced Tensor Parallelism. I have been a fan of ExLlamaV2 for quite sometime, and it was my main driver inference engine when I had 1 & 2 GPUs. I haven’t done extensive tests yet with its newly implemented Tensor Parallelism, but it seemed to work from my initial trials. ExLlamaV2 also introduced its own EXL2 quantization to the world, which is now supported by multiple inference engines due to its
Llama.cpp is the most popular Inference Engine out there. The Open Source community around it is amazing, and usually pretty fast at supporting new models, architectures, and quantizations, and it offers CPU offloading out of the box. Unfortunately it does not –and probably would never– support Tensor Parallelism because most people do not go about spending thousands of dollars on fast-depreciating assets like I do 🤷.
Finally, I wanted to mention the popular Ollama. Ollama is a wrapper around llama.cpp, and in my opinion it is a tool that just sets environment variables, do a bad job at offloading calculations, and lead to a lot of frustration. It is great if you have only 1 GPU and don’t want to do much except running basic models for chat sessions; anything beyond that and it isn’t worth using.
Tensor Parallelism
Tensor Parallelism is just one caveat of inference engines. Inference engines need to 1) implement model’s architectures, 2) implement quantization kernels, and 3) make sure that they support the model architecture in said quantizations. You cannot quantize a model using a certain algorithm, EXL2 for example, without ExLlamaV2’s algorithm support for said model’s architecture. In fact, ExLlamaV2 does not support DeepSeek v2 MoE architecture, and if you look up an EXL2 quantization of it on huggingface , you won’t find any DeepSeek 2 or 2.5 quantizations. Neither does TensorRT-LLM by the way –which is developed by Nvidia!
Side note: I actually started looking into contributing to the project with that implementation and writing about it as I go, all pending my tests of the engine’s Tensor Parallelism features. Might be a fun side-project and write-up. So stay tuned for updates regarding that.
Quantization, Mixed Precision, Weights and Activations
There are several Mixed Precision quantizations out there, but for huge models like Llama 3.1 405B, and DeepSeek V2.5, W4A16 is the only one my AI Server can run them in at the moment.
W4A16 means training a model with 4-bit weights and 16-bit activations quantization which leverages lower precision for storage and computation of weights, leading to a reduction in storage and memory usage, and increasing computational efficiency, all while using higher precision activations to maintain model accuracy and stability/coherence.
Imagine you’re running a budget-friendly tech startup from your garage. Your team (weights) only has tiny offices (4-bit) to save on rent, which cuts down on costs and speeds up communication between the relevant team members. But when it’s time for high-stake decision making (activations), you use a spacious, well-equipped conference rooms (16-bit) to make sure all the big decisions are made accurately and effectively, and everyone is involved. In other words, it is shortcuts (weights) and detailed paths to the shortcuts (activations).
Given my limited resources—I’m not exactly swimming in high-powered server farms—using W4A16 is like having a tiny, super-efficient factory right in my basement, allowing me to run my model without further breaking the bank or my setup. One can only dream of a GPU cluster w/ 2-4x nodes and 8x H100s/node. 🤤
To summarize: Quantizations are compression algorithms that are applied to the weights and activations on every layer in a neural network. W4A16 is a quantization algorithm. There are many others, and what we need to keep in mind is that a quantization–compression–algorithm needs to understand the shape–model architecture–it is dealing with—and inference engines need to know both the model architecture and the quantization algorithm for the general algorithm and the specific model. Below is a comparison on different quantization algorithms.
As I was writing this blogpost, at 4:48 AM exactly, I came across this paper A Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B which was released only 6 hours ago. I was trying to find a good way to convey what quantizations do.
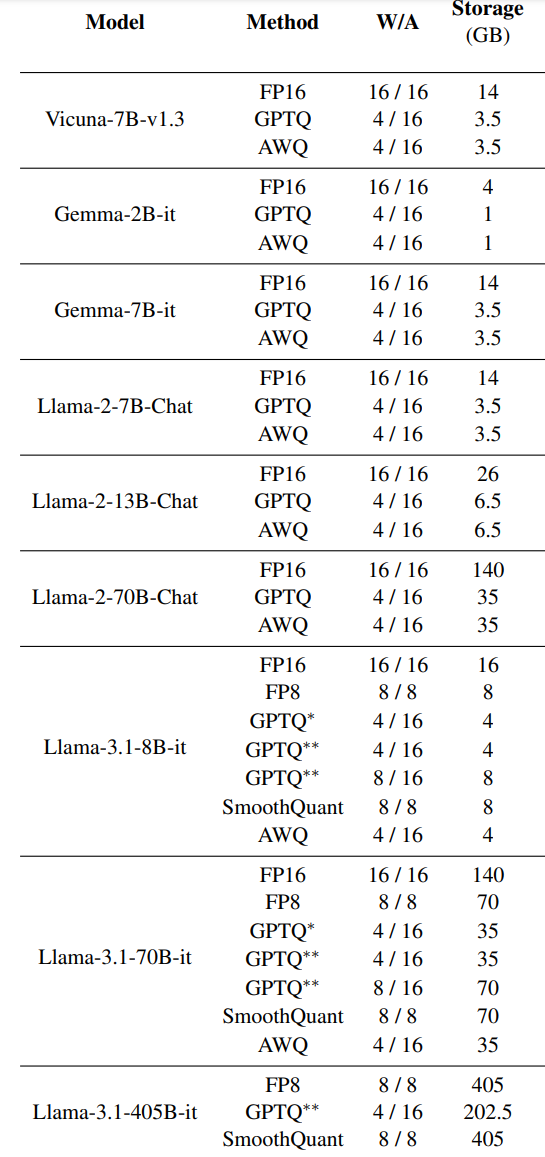
∗∗ uses vLLM project’s LLM-Compressor, by vLLM
for GPTQ quantization
There is a lot more to say about quantization. For example, just recently a new quantization algorithm became available, AQLM, and they published their work promising Extreme Compression of Large Language . I tweeted about it given how impressive the results were. I hope they stick around. Quantization is an area that needs a new and decent standard. Full-weights are very expensive, quantizations can decrease a model costs by up to 75% without any noticeable decrease in accuracy.
I am reading about AQLM, and I am impressed with the benchmarks for their Llama 3.1 70B, it went down in size from 141 GB to 22 GB, and the evaluations did not drop by much: https://t.co/x8MvJeOluN
— Ahmad (@TheAhmadOsman) September 17, 2024
Quantization works with vLLM. If proven across the board, this can be a game…
Tensor Parallelism, Again!
As we concluded, for an agentic system batch inference is crucial. The cover of this blogpost is a screenshot from a script that I ran with 50 asynchronous requests, ~2k tokens per request, which all-in-all took 2mins 29secs with vLLM running Llama 3.1 70B BF16. It could have been a lot faster if I used an INT8 quantization or lower. And adding speculative decoding and/or embedding model in the mix would make things even faster.
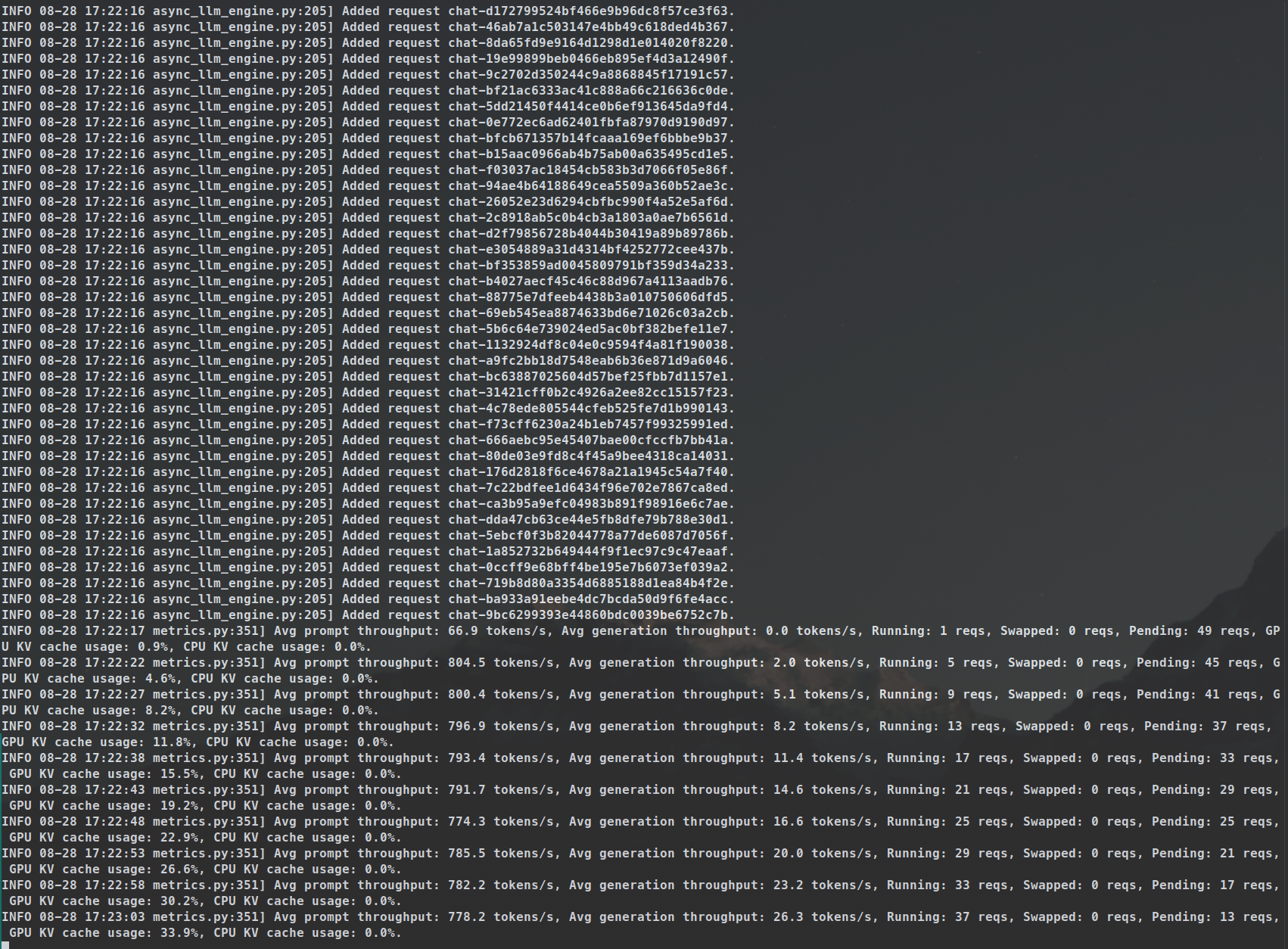
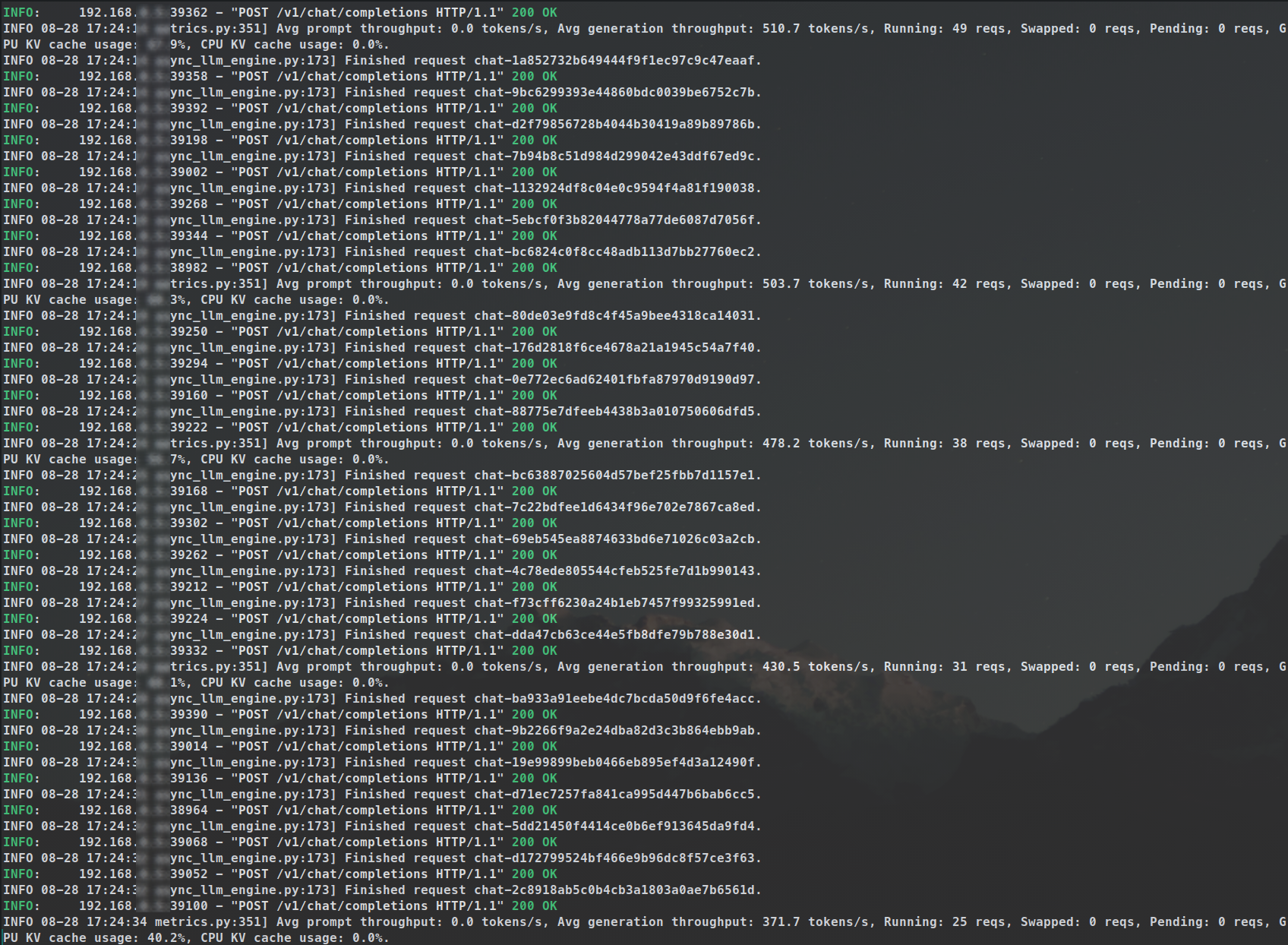
Later on, I ran that script with over 10k requests for synthetic data generation, and the runtime held true.
As I mentioned in my first blogpost, Tensor Parallelism (TP) is important (and as a rule of thumb, TP loves 2^n hence the 8x GPUs); and in the case of an agentic system, running batch inference is crucial and that relies on Tensor Parallelism. You want to be able to have many iterations running of the same thing, trying different things, correcting each other, improving, etc. There is a whole world of possibilities to explore here and that makes me excited–and as you can see, keeps me up all night. 😅
Until just a couple of weeks ago, the only hope I had for running a quantized DeepSeek v2.5 MoE model was in Llama.cpp implementing Tensor Parallelism. GGUFs are everywhere, but as we concluded that would mean I cannot use my GPUs in an efficient or effective manner. vLLM and Aphrodite support the GGUF quantization, however, without Tensor Parallelism implementation and offloading to 1 GPU only!
The other option was to rely on bitsandbytes quantization for the model, which is supported natively by Hugging Face’s Text Generation Interface
, however, it mainly implements its Cuda features for data-center grade GPUs, and even then, it is also known for not-so-great performance. Not optimal.
I looked at other options, and in one of my Google searches, LMDeploy teased me that it supports W4A16 of DeepSeek v2 architecture. However, it was only incorrect keyword matching.
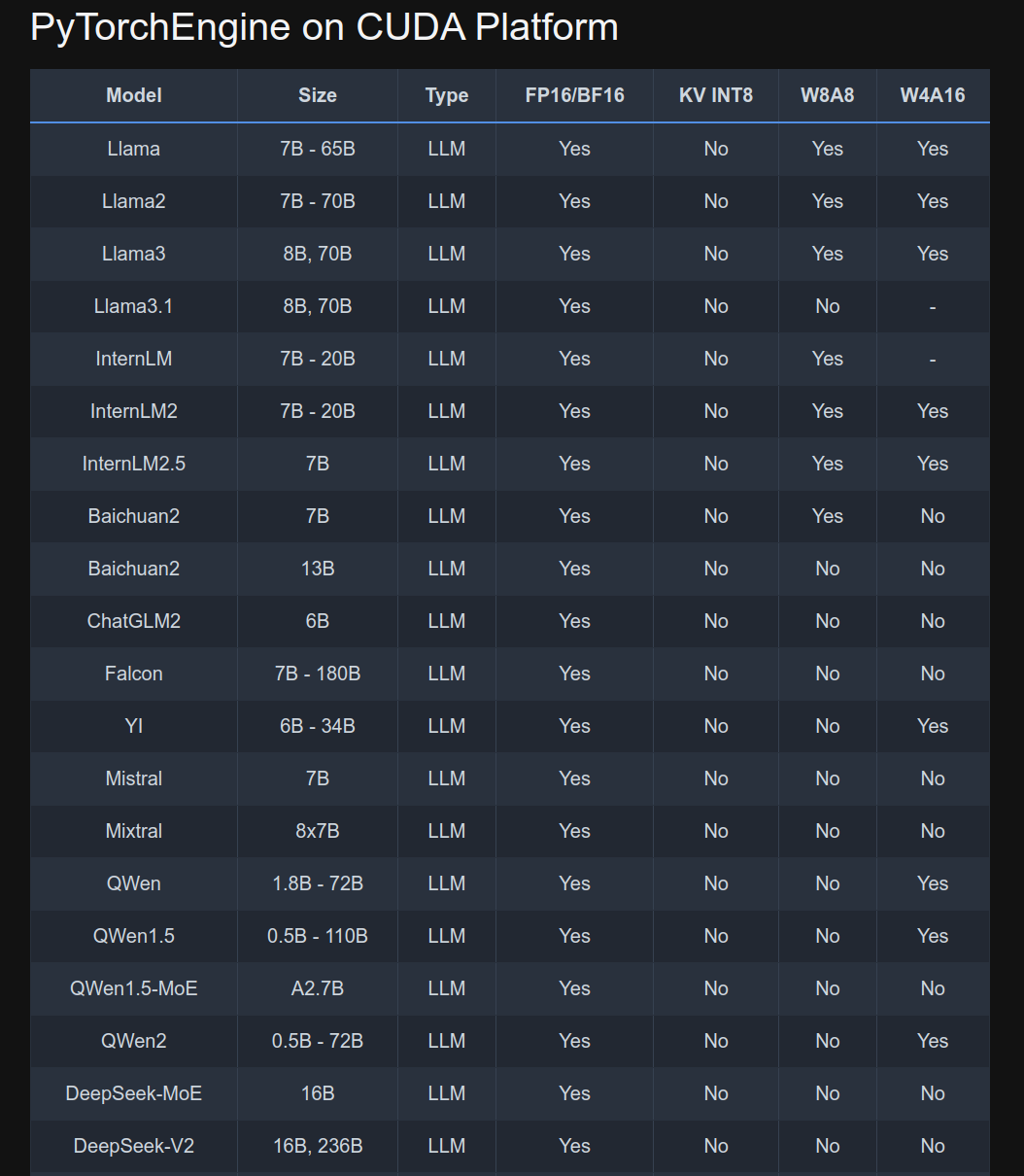
It was not until recently that the Mixed Precision quantization for the DeepSeek v2 MoE architecture became available in the vLLM kernel. In parallel, the LLM Compressor library also implemented the quantization algorithm for it. Finally!!!
Let’s Quantize
DeepSeek v2.5 is around 500GB in BF16 Full Precision. I finished downloading it a while ago (thank god for gigabit internet!!!) and started a quantization job.
I am going to let it run for now. It seems to be going up in the number of hours, and it might not be running optimally so I might still need to play with it. I plan on reporting back on this in a later post. For now, I feel like I am making progress, and that’s good. 😁
What’s Next?
I started this blogpost originally planning on writing about something completely different that I will now leave for a later time. As I am wrapping up this post, it is almost 11 AM, and I do not mind that. I followed my curiosity, learned a few new things, and made some progress.
Originally I planned on including sections on Speculative Decoding, Embedding Models, and Sampling Parameters in this blogpost, but I came to realize that I should leave that to a later blogpost in this series. I do not want to make this blogpost any longer and I want to write about them properly.
Next blogpost I plan on addressing the main pain points of the hardware build and following up on the most-asked questions I received on the first blogpost. I apologize for taking so long to get that out there, but it is taking me more than I expected to properly cover everything I want.
I’ll be back with more. Stay tuned.
P.S. This blogpost was originally titled SWE Agentic Framework, MoEs, Quantizations & Mixed Precision, Batch Inference, LLM Architectures, vLLM, DeepSeek v2.5, Embedding Models, and Speculative Decoding: An LLM Brain Dump